Origin's Blog
Writing a Simple HTTP Client
You might always wanted to write your own HTTP client from scratch. Or maybe you want to do it for some project you have planned, but you don’t want to necessarly overuse vendors code for
code size and reliability reasons. Whatever it is, this post will try to explain each step of how you can get going with building a simple HTTP client and by the end of it, even shows code
for how it might be implemented in C. But this is ofcourse not bound specifically to C and can be ported to any language, given that it has access to system sockets.
Theory lesson
Before starting into the fun part, we need to first talk about the rules, the “concepts” of how data is transferred and how to make HTTP requests. First of all I want to tackle the question of what HTTP stands for. HTTP (Hypertext Transfer Protocol) is a protocol used for fetching resources, such as HTML documents.
It is the foundation of any data exchange on the Web and it is a client-server protocol, which means requests are initiated by the recipient, usually the web browser.
In simpler terms, client and server are both compliant to the HTTP protocol and we use its rules to fetch resource data from the server by using its declarative syntax. We communicate
with the server by exchanging individual messages, instead of opening a stream to transfer data. Usually a HTTP client sends a request to the HTTP server, which returns a response.
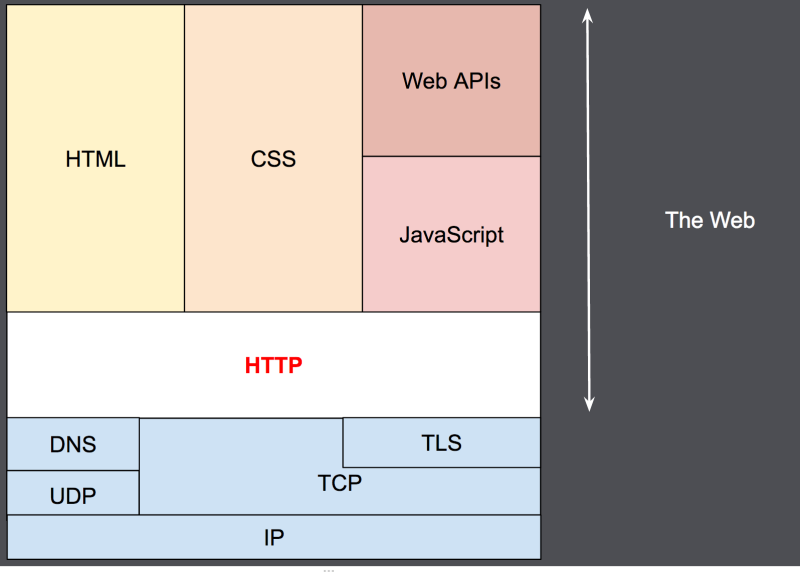
(Source: Mozilla)
{kind=link}
By the previous depiction, the image above shows, that HTTP is the entry protocol for the web, which allows clients and servers alike to communicate with the “web” construct. Also as it is shown, HTTP is relying on many different protocols underneath it in order for the packets to be sent, as well as received reliably. In this post I want to ignore the TLS/SSL protocol, making things more simple to understand as I want to show the abstract view of how such connections are being made, instead of how we can implement it for each and every scenario. For that use a library, instead of reading this!
Thinking about where we want to start, as the title might suggest, we want to write the “client” part of the protocol, i.e. initiating the request. For our example, we directly connect
to a given server, without using a proxy in between. But the way of how we communicate should be analogous. Additionally we are going to ignore some of the features HTTP offers, such
as caching and sessions.
Go with the flow
To start requesting something from a remote server, we have to perform a series of tasks. The steps are:
- Open a (preferably) TCP connection
- Send a HTTP message
- Read a response
- Close or reuse the connection
Multiple connections may be made simultaneously, connections can be reused and don’t have to be re-initiated each time.
Let’s talk about each step in detail:
- Open a TCP connection
The arguably most difficult part of all presented steps is really the first one. In the Unix-world, we create a file descriptor, which we will use to communicate with our endpoint. This is also called a socket(). Its purpose, or “domain”, will be for the IPv4 Internet protocols, so we use the operating systems native implementation of the protocol, instead of reinventing the wheel (do so if you are interested how your car works). The protocol is implementing version 4, described in RFC 791 and RFC 1122. We open it as a TCP socket for reliable communication. Then we connect to a remote address with the given socket to initiate a new connection to a HTTP server. And that’s basically it.
In the end, we only have to do two function calls to connect to a HTTP server. The same principle also applies to Windows users, except that the function parameters are slightly different named. Please read your API manual for further information. With an open connection ready at hand, we need to send data to the remote, so let’s move on.
- Send a HTTP message
Before we can get any information from the HTTP server, we have to tell what we want to fetch and how we want to fetch. This information is provided by the HTTP request, which includes a method, path, protocol version and the HTTP headers. It is roughly of shape:
GET / HTTP/1.1
Host: origins-blog.com
Accept-Language: en
This request would tell the HTTP server, that we want to use the method GET, so we want to retrieve some data from the server. The next parameter, the “/”, is indicating the path of
where our data lives on the server, that we want to fetch. And the last parameter is indicating the HTTP protocol version that we are using. In this case it is HTTP/1.1.
Furthermore we have included two more values in the HTTP headers which are used to tell the server more information about a given request.
The first is the Host, that is the host to which the request is being sent. In this case the value is origins-blog.com.
Then we have additionally the Accept-Language key, which is indicating the natural language or the preferred locale that the client wants to use. In this case we have set it to
en, indicating that we want the content returned in English language (btw. this blog is in English only). You might start to see a pattern here, each and every HTTP header is provided
in this <key>:<value> syntax. Additionally a body may be sent, if you want data to be processed on the server. To indicate the end of a request, we must use an additional new line.
If a new line character is read, while no <key>:<value> was read before-hand, the request is considered complete and the server will start responding.
We send data to the server, by calling send() with the provided socket and the given HTTP request. It is important that the socket is connected (Recipient is known) before sending data to it. Also we must check if all data was sent, by reading the bytes and increment pointers, to send all of the data. This happens, if the underlying physical medium has insufficient space. After writing all data to the socket, we can finally go to step 3.
- Read a response
For reading whatever the server is returning, we are going to use an I/O multiplexer approach. Useful for when multiple requests are being made simultaneously, we don’t have to fetch their responses sequentially. We treat our response as a set of responses now. We wait until one or more file descriptors are ready, by calling select() on them. This is the point, where we should realize that our actions take time. We cannot possibly know when we receive a response, or even if we receive a response at all. This is why we have to wait until a socket is signaling, that it is ready to be read. We do that by reading how many bytes have been received, preparing a buffer and storing all bytes in it. Now we have successfully read the response and can do whatever we want with the data. Otherwise a timeout routine must be implemented to possibly let the user know, that no response came from the server.
- Close or reuse the connection
We can either go from step 2) now and request more data or we close the connection and start from step 1) again.
To more visualize of what these 4 steps roughly represent, look at the following call graph
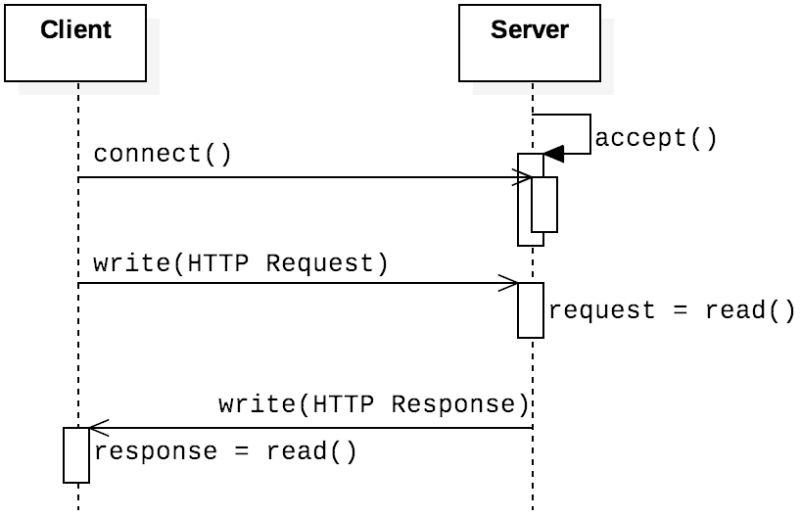
(Source: Computer Systems Fundamentals)
{kind=link}
Example Implementation
Now I show off how you might want to use it in C, but any language with access to system functions will suffice. I will primarly use the Linux headers for this task.
The used header files are denoted in the following list:
#include <errno.h>
#include <netdb.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/select.h>
#include <sys/socket.h>
#include <unistd.h>
First of all, let’s start with a simple bail function, which returns an error exit-code
and prints errno as string, together with its passed context. The function looks like this
int bail(const char *context) {
fprintf(stderr, "%s: %s\n", context, strerror(errno));
return EXIT_FAILURE;
}
The following code is all inside the context of the main function.
Let’s start by defining some variables that make it easier to fetch something from a given service
const char *host = "info.cern.ch";
int sock = -1;
For our example, we will try to fetch the contents of the very first website. We have defined the host we want to fetch from and the address of our future file descriptor, that we will set in a moment. But having the information in plain text is useless for our system, we need it in preferably a computer understandable format in network byte order. In this step we are converting the hostname to an address
int rv; // Store the return value
struct addrinfo *result; // Pointer to where we store the addresses
struct addrinfo *rp; // Later used to connect to address
struct addrinfo hints; // Indicates, which service address we want to get
// Set the entire struct to 0
memset(&hints, 0, sizeof(hints));
// Set hints to allow for IPv4 address and for a TCP connection
hints.ai_family = AF_INET;
hints.ai_socktype = SOCK_STREAM;
rv = getaddrinfo(host, "http", &hints, &result);
if(rv != 0) {
fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(rv));
return bail("Could not find address of remote service");
}
With this, we can go ahead, create our socket and connect to it
// Since getaddrinfo() returns a list of address structures
// Try each address until we successfully connect()
// If socket() (or connect()) fails, we (close the socket and)
// try the next address
for (rp = result; rp != NULL; rp = rp->ai_next) {
sock = socket(rp->ai_family, rp->ai_socktype, rp->ai_protocol);
if (sock == -1) {
continue;
}
if (connect(sock, rp->ai_addr, rp->ai_addrlen) != -1) {
break;
}
close(sock);
}
// No longer needed
freeaddrinfo(result);
if (rp == NULL) {
return bail("Could not connect to remote server");
}
Now that we have a connection setup, we can go ahead and build our request and send it to the server
// Building the request and getting its length
const char *request = "GET / HTTP/1.1\r\n"
"Host: info.cern.ch\r\n"
"Accept-Encoding: identity\r\n"
"\r\n"; // The last \r\n is important! Otherwise HTTP expects more data
int requestLen = strlen(request);
// Making sure, all the bytes from the request are being sent
while (requestLen > 0) {
int n = send(sock, request, requestLen, 0);
if (n < 0) {
return bail("The amount of sent bytes is negative");
}
requestLen -= n;
request += n;
}
After sending all the data, we need to retrieve data from the server
// Amount of outstanding requests, important because we multiplex multiple connections into a file descriptor set
int outstanding = 1;
while (outstanding) {
fd_set fds;
FD_ZERO(&fds);
FD_SET(sock, &fds);
struct timeval tv;
tv.tv_sec = 0;
tv.tv_usec = 0;
int r = select(sock + 1, &fds, NULL, NULL, &tv);
if (r < 0) {
return bail("File descriptor set is has invalid state");
}
if (FD_ISSET(sock, &fds) == 0) {
// No data needs to be read, so we continue in the loop
continue;
}
unsigned char buf[2048];
int a = recv(sock, (char *)buf, sizeof(buf), 0);
if (a < 0) {
return bail("Read a negative amount of bytes from socket");
}
// In this case, data needs to be read from the socket
if (a != 0) {
int used = 0;
while (used < a) {
// I'm feeling lazy, so I just print the data
printf("%s", buf);
used += a - used;
}
// In this case, all the data from the socket was read
} else {
// For multiple connection, you'd probably want this to decrement instead of setting it to 0
outstanding = 0;
// Closing socket
close(sock);
sock = -1;
}
}
As I’m lazy, I’m only gonna print the response and close the connection afterwards. You can do whatever you want with the response.
Now that you have understood a little more of how to initiate a simple HTTP request, nothing is stopping you from trying it out with HTTP version 2 or even HTTPS with OpenSSL.
Download the full source code
Sources
- OpenCSF Link to TCP Socket Programming: HTTP
- Mozilla Link to An overview of HTTP
- Mozilla Link to HTTP headers
- Scumways Link to HappyHTTP (Site is dead)
- Scumways HappyHTTP Source Code Link to self-hosted copy of HappyHTTP